Central Limit Theorem
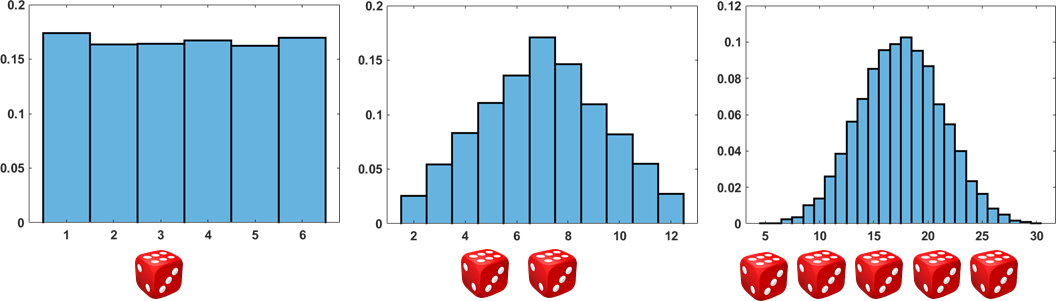
The law of large numbers tells us the mean of the sample average \(\overline{X}_N = (1/N)\sum_{n=1}^N X_n\). However, if you recall our experiment of throwing \(N\) dice and inspecting the PDF of the sum of the numbers, you may remember that the convolution of an infinite number of uniform distributions gives us a Gaussian distribution. For example, we show a sequence of experiments in Figure 6.13. In each experiment, we throw \(N\) dice and count the sum. Therefore, if each face of the die is denoted as \(X_n\), then the sum is \(X_1 + \cdots + X_N\). We plot the PDF of the sum. As you can see in the figure, \(X_1 + \cdots + X_N\) converges to a Gaussian. This phenomenon is explained by the Central Limit Theorem (CLT).
What does the Central Limit Theorem say? Let \(\overline{X}_N\) be the sample average, and let \(Z_N = \sqrt{N}\left(\frac{\overline{X}_N-\mu}{\sigma}\right)\) be the normalized variable. The Central Limit Theorem is as follows:
:
The CDF of \(Z_N\) is converging pointwise to the CDF of Gaussian(0,1).
Note that we are very careful here. We are not saying that the PDF of \(Z_N\) is converging to the PDF of a Gaussian, nor are we saying that the random variable \(Z_N\) is converging to a Gaussian random variable. We are only saying that the values of the CDF are converging pointwise. The difference is subtle but important.
To understand the difficulty and the core ideas, we first present the concept of convergence in distribution.
6.4.1Convergence in distribution
Let \(Z_1,\ldots,Z_N\) be random variables with CDFs \(F_{Z_1},\ldots,F_{Z_N}\) respectively. We say that a sequence of \(Z_1,\ldots,Z_N\) converges in distribution to a random variable \(Z\) with CDF \(F_Z\) if
for every continuous point \(z\) of \(F_Z\). We write \(Z_N \overset{d}{\rightarrow} Z\) to denote convergence in distribution.
This definition involves many concepts, which we will discuss one by one. However, the definition can be summarized in a nutshell as follows.
Convergence in distribution = values of the CDF converge.
(Bernoulli) Consider flipping a fair coin \(N\) times. Denote each coin flip as a Bernoulli random variable \(X_n \sim \text{Bernoulli}(p)\), where \(n = 1,2,\ldots,N\). Define \(Z_N\) as the sum of \(N\) Bernoulli random variables, so that
We know that the resulting random variable \(Z_N\) is a binomial random variable with mean \(Np\) and variance \(Np(1-p)\). Let us plot the PDF \(f_{Z_N}(z)\) as shown in Figure 6.14.
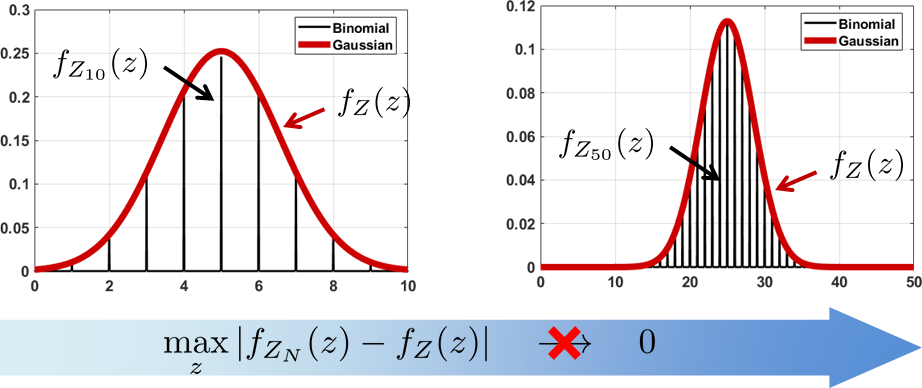
The first thing we notice in the figure is that as \(N\) increases, the PDF of the binomial has an envelope that is “very Gaussian”. So one temptation is to say that the random variable \(Z_N\) is converging to another random variable \(Z\). In addition, we would think that the PDFs converge in the sense that for all \(z\),
where \(\mu = Np\) and \(\sigma^2 = Np(1-p)\).
Unfortunately this argument does not work, because \(f_Z(z)\) is continuous but \(f_{Z_N}(z)\) is discrete. The sample space of \(Z_N\) and the sample space of \(Z\) are completely different. In fact, if we write \(f_{Z_N}\) as an impulse train, we observe that
Clearly, no matter how big the \(N\) is, the difference \(|f_{Z_N}(z) - f_Z(z)|\) will never go to zero for non-integer values of \(z\). Mathematically, we can show that
as \(N \rightarrow \infty\). \(Z_N\) is a binomial random variable regardless of \(N\). It will not become a Gaussian.
If \(f_{Z_N}(z)\) is not converging to a Gaussian PDF, how do we explain the convergence? The answer is to look at the CDF. For discrete PDFs such as a binomial random variable, the CDF is a staircase function. What we can show is that
The difference between the PDF convergence and the CDF convergence is that the PDF does not allow a meaningful “distance” between a discrete function and continuous function. For CDF, the distance is well defined by taking the difference between the staircase function and the continuous function. For example, we can compute
and show that
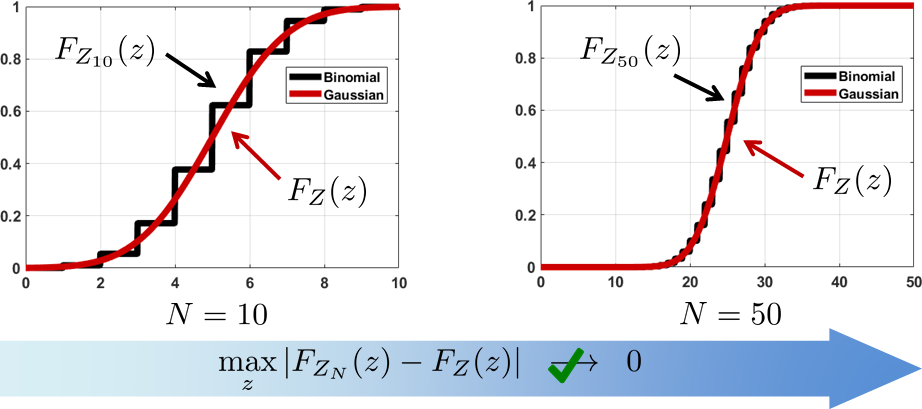
We need to pay attention to the set of \(z\)'s. We do not evaluate all \(z\)'s but only the \(z\)'s that are continuous points of \(F_Z\). If \(F_Z\) is Gaussian, this does not matter because all \(z\)'s are continuous. However, for CDFs containing discontinuous points, our definition of convergence in distribution will ignore these discontinuous points because they have a measure zero.
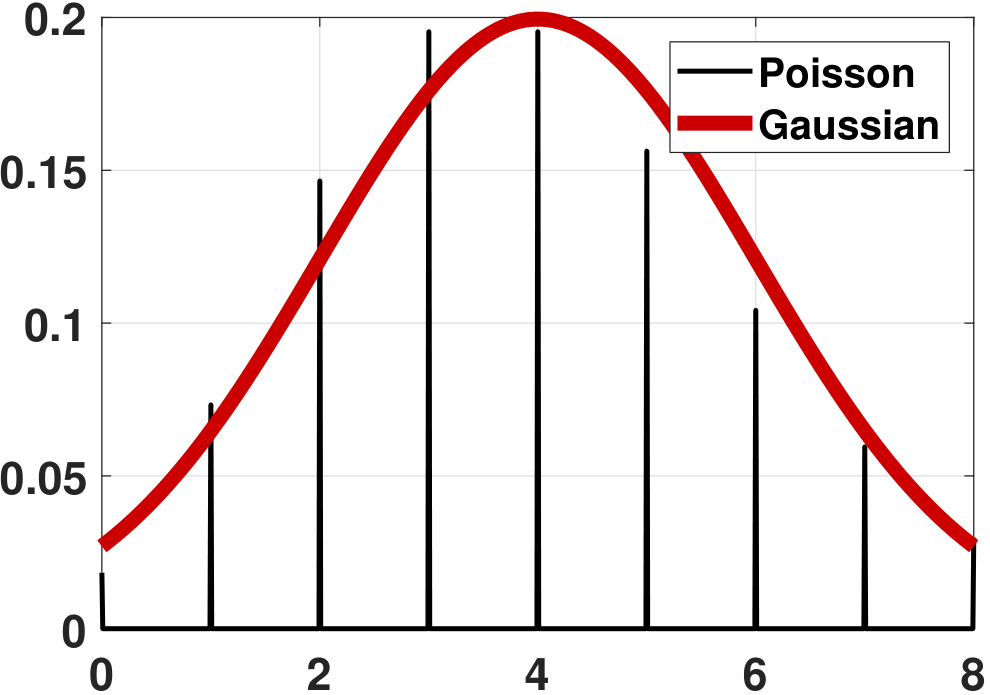
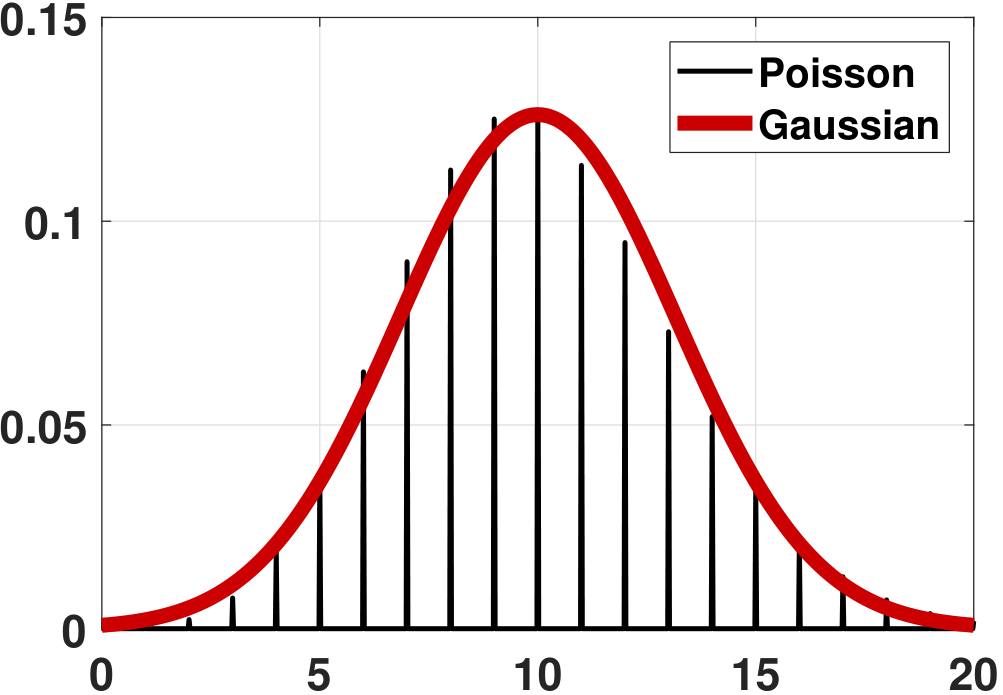
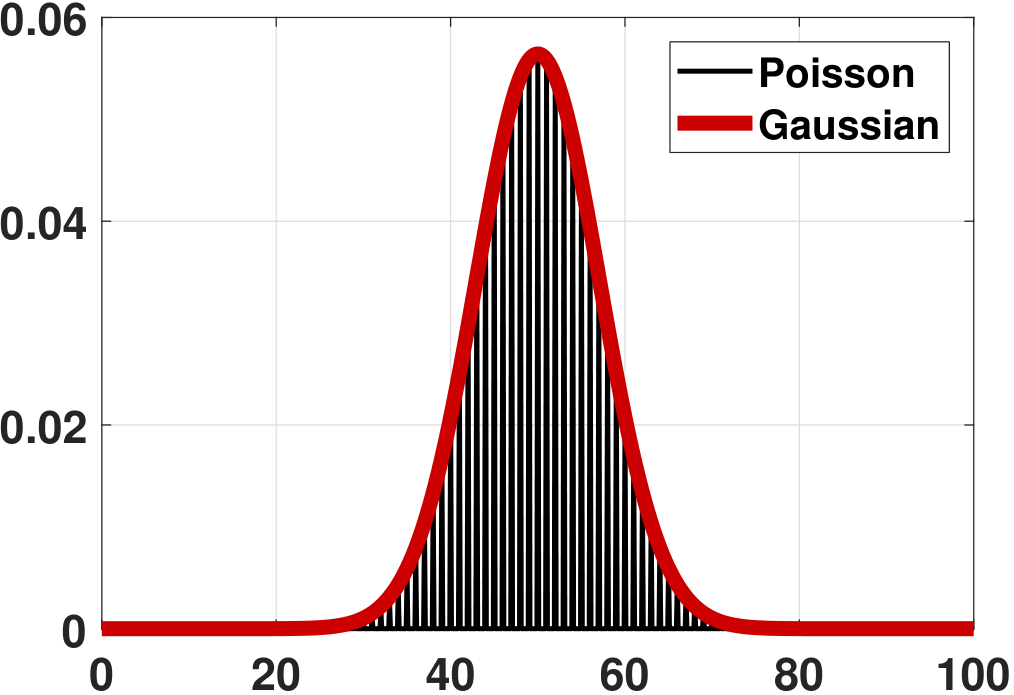
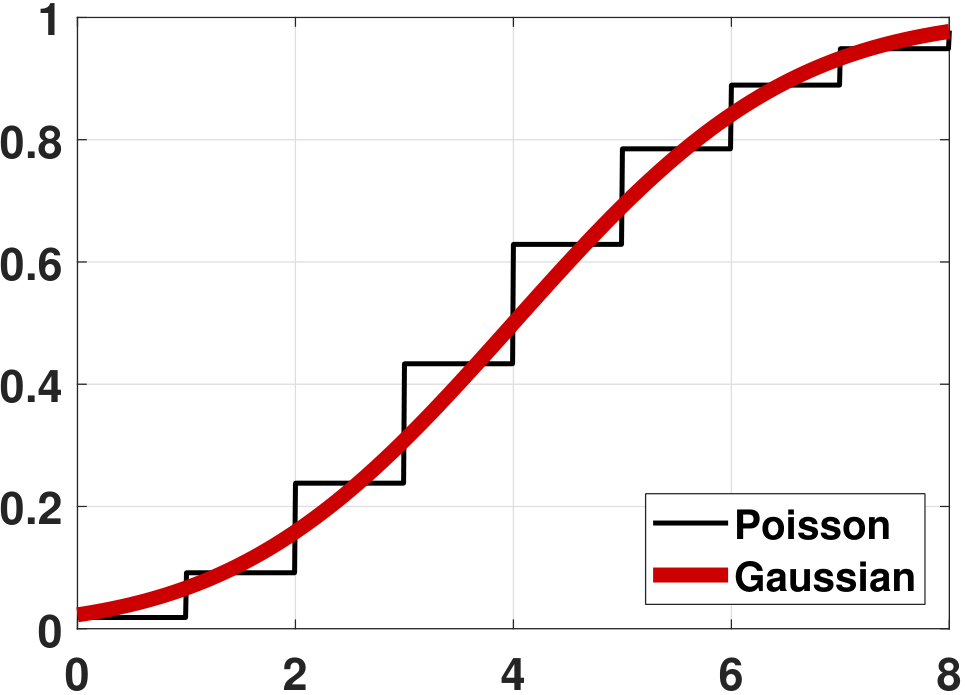
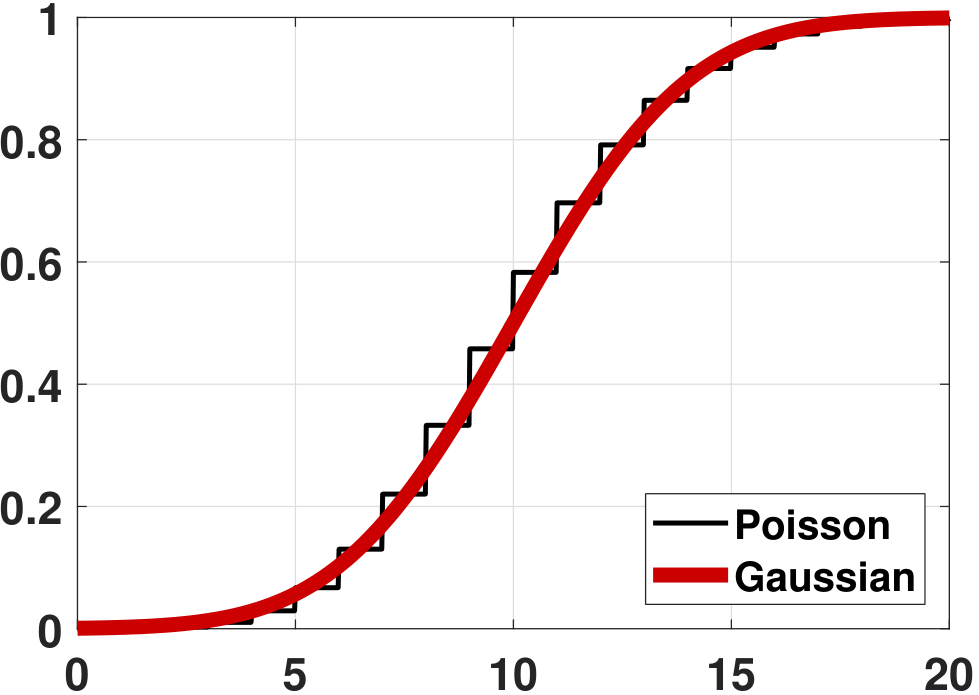
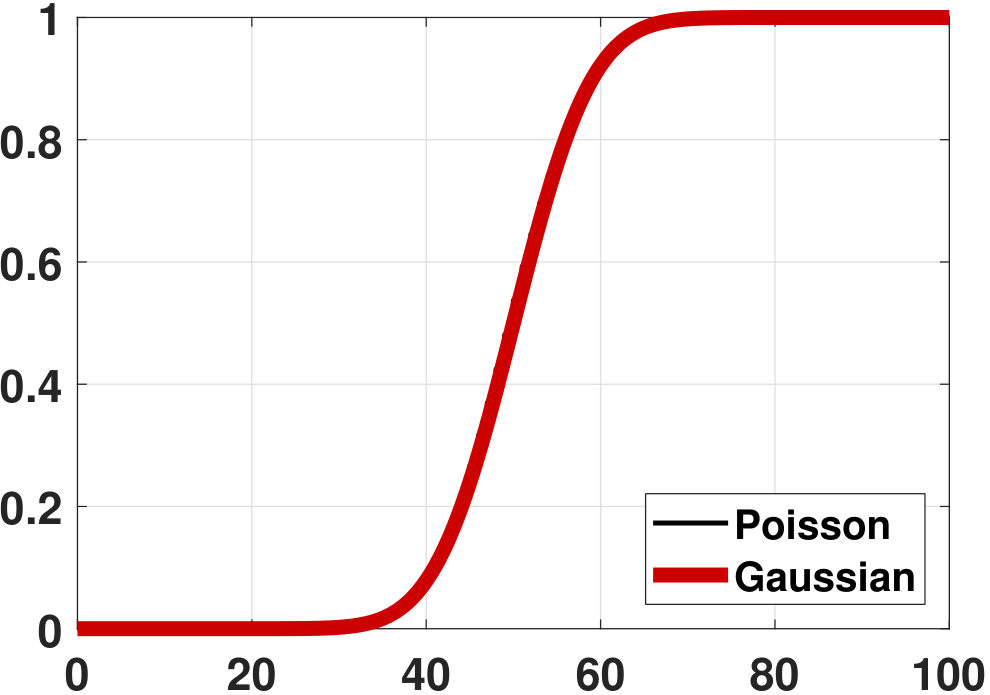
(Poisson) Consider \(X_n \sim \text{Poisson}(\lambda)\), and consider \(X_1,\ldots,X_N\). Define \(Z_N = \sum_{n=1}^N X_n\). It follows that \(\E[Z_N] = \sum_{n=1}^N \E[X_n] = N\lambda\) and \(\Var[Z_N] = \sum_{n=1}^N \Var[X_n] = N\lambda\). Moreover, we know that the sum of Poissons remains a Poisson. Therefore, the PDF of \(Z_N\) is
where \(\mu = N\lambda\) and \(\sigma^2 = N\lambda\). Again, \(f_{Z_N}\) does not converge to \(f_Z\). However, if we compare the CDF, we can see from Figure 6.16 that the CDF of the Poisson is becoming better approximated by the Gaussian.
Interpreting “convergence in distribution”. After seeing two examples, you should now have some idea of what “convergence in distribution” means. This concept applies to the CDFs. When we write
we mean that \(F_{Z_N}(z)\) is converging to the value \(F_Z(z)\), and this relationship holds for all the continuous \(z\)'s of \(F_Z\). It does not say that the random variable \(Z_N\) is becoming another random variable \(Z\).
\(Z_N \overset{d}{\longrightarrow} Z\) is equivalent to \(\lim_{N \rightarrow \infty}F_{Z_N}(z) = F_Z(z)\).
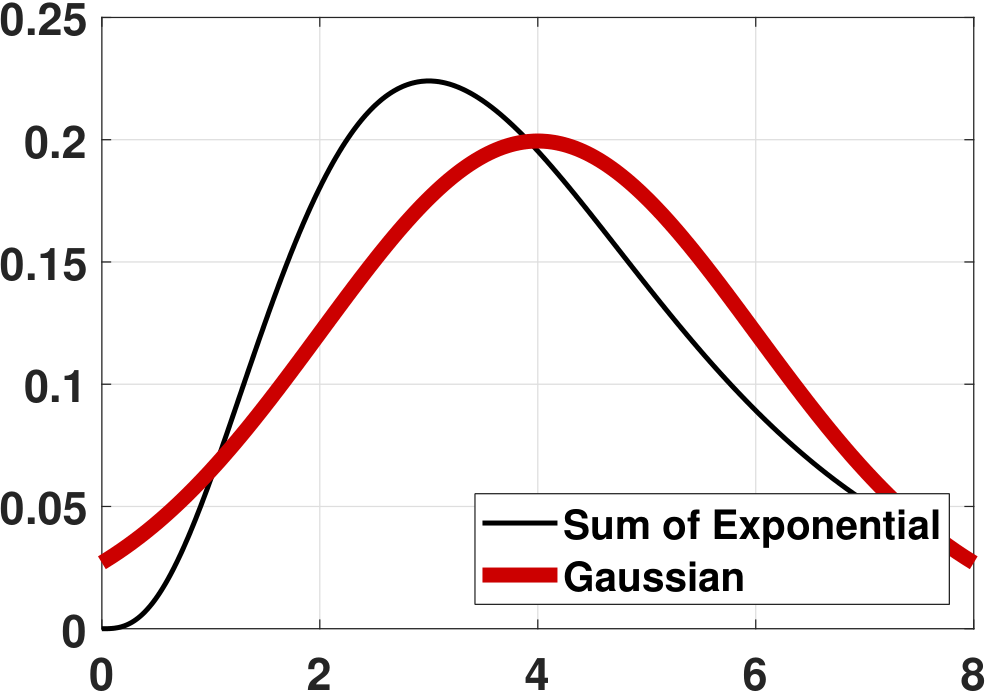
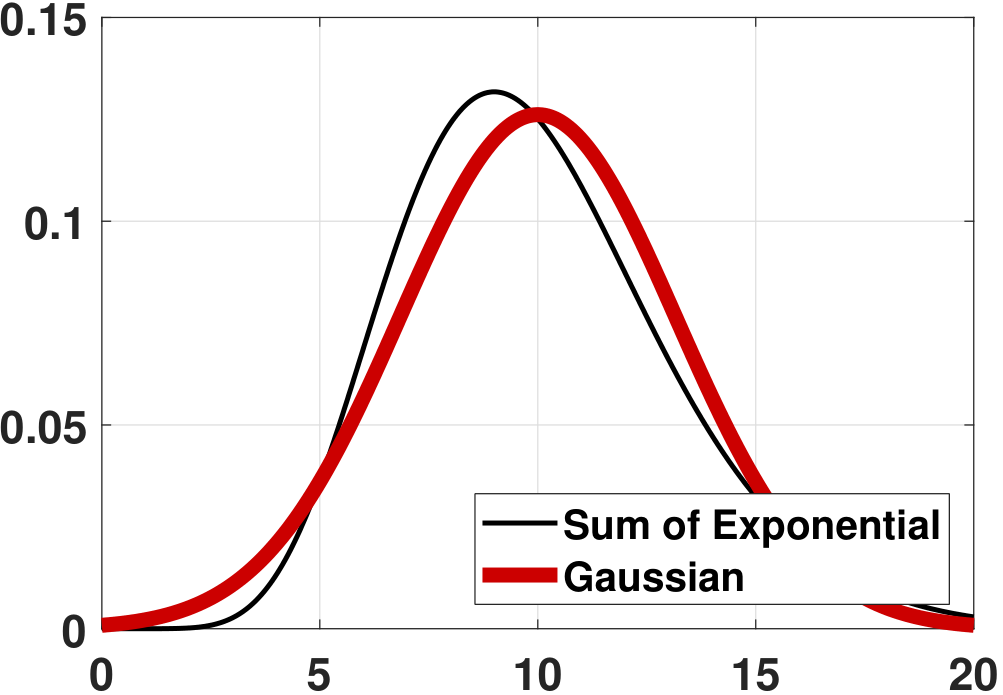
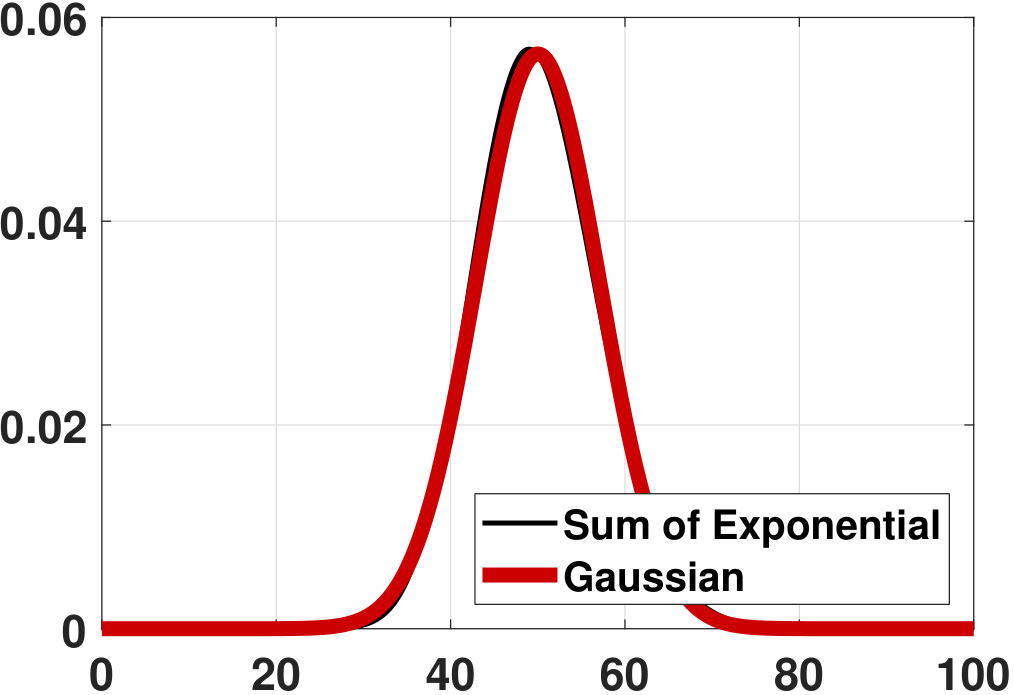
(Exponential) So far, we have studied the sum of discrete random variables. Now, let's take a look at continuous random variables. Consider \(X_n \sim \text{Exponential}(\lambda)\), and let \(X_1,\ldots,X_N\) be i.i.d. copies. Define \(Z_N = \sum_{n=1}^N X_n\). Then \(\E[Z_N] = \sum_{n=1}^N \E[X_n] = N/\lambda\) and \(\Var[Z_N] = \frac{N}{\lambda^2}\). How about the PDF of \(Z_N\)? Using the characteristic functions, we know that
Therefore, the product is
This resulting PDF \(f_{Z_N}(z) = \frac{\lambda^N}{(N-1)!}z^{N-1}e^{-\lambda z}\) is known as the Erlang distribution. The CDF of the Erlang distribution is
where the last integral is known as the incomplete gamma function, evaluated at \(z\).
Given all of these, we can now compare the PDF and the CDF of \(Z_N\) versus \(Z\). Figure 6.17 shows the PDFs and the CDFs of \(Z_N\) for various \(N\) values. In this experiment we set \(\lambda = 1\). As we can see from the experiment, the Erlang distribution's PDF and CDF converge to a Gaussian. In fact, for continuous random variables such as exponential random variables, we indeed have the random variable \(Z_N\) converging to the random variable \(Z\). This is quite different from discrete random variables, where \(Z_N\) does not converge to \(Z\) but only \(F_{Z_N}\) converges to \(F_Z\).
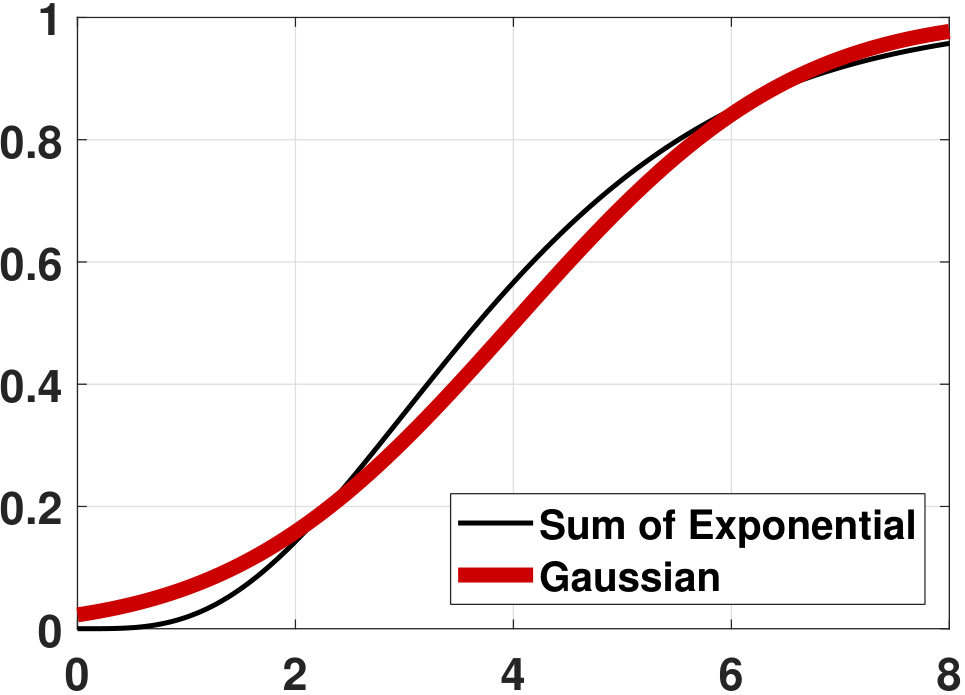
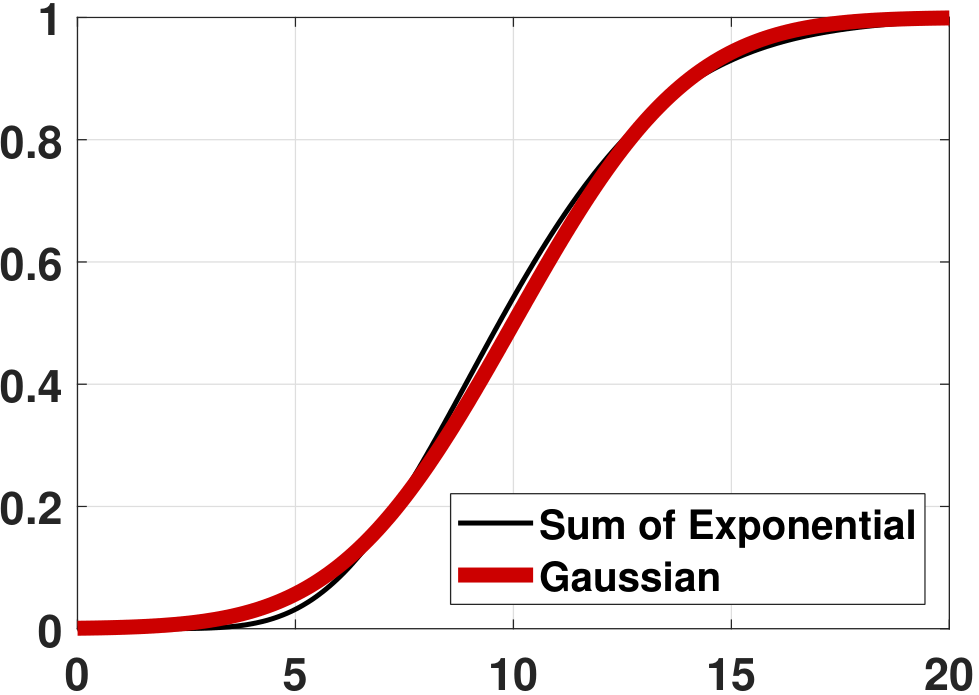
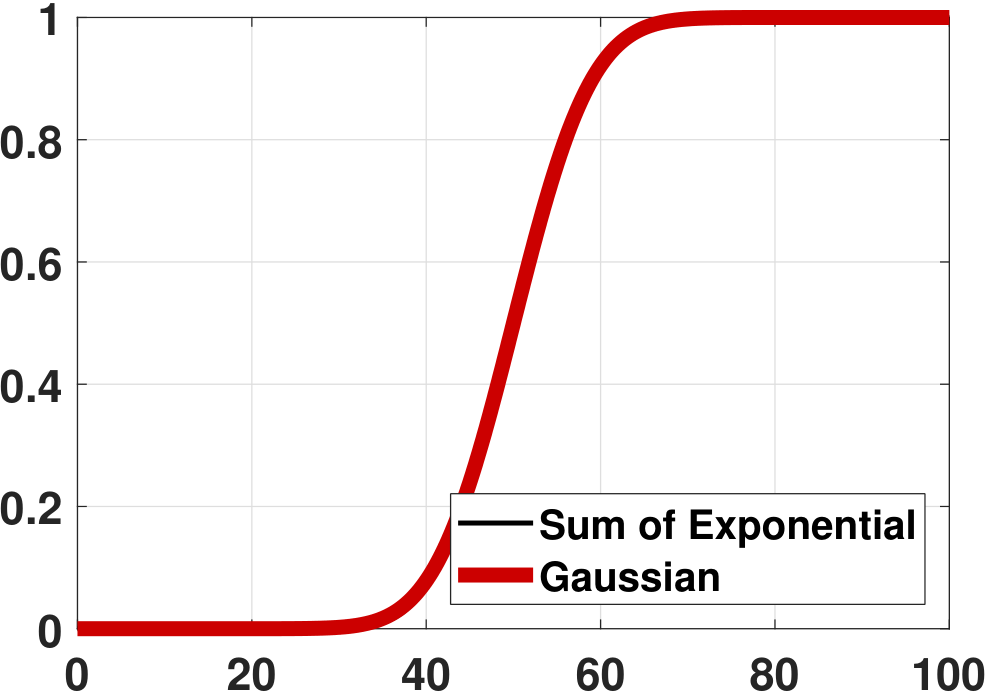
Is \(\overset{d}{\longrightarrow}\) stronger than \(\overset{p}{\longrightarrow}\)? Convergence in distribution is actually weaker than convergence in probability. Consider a continuous random variable \(X\) with a symmetric PDF \(f_X(x)\) such that \(f_X(x) = f_X(-x)\). It holds that the PDF of \(-X\) has the same PDF. If we define the sequence \(Z_N = X\) if \(N\) is odd and \(Z_N = -X\) if \(N\) is even, and let \(Z = X\), then \(F_{Z_N}(z) = F_Z(z)\) for every \(z\) because the PDFs of \(X\) and \(-X\) are identical. Therefore, \(Z_N \overset{d}{\rightarrow} Z\). However, \(Z_N \not \overset{p}{\rightarrow} Z\) because \(Z_N\) oscillates between the random variables \(X\) and \(-X\). These two random variables are different (although they have the same CDF) because \(\Pb[X=-X] = \Pb[\{\omega: X(\omega)=-X(\omega)\}] = \Pb[\{\omega: X(\omega)=0\}] = 0\).
6.4.2Central Limit Theorem
Let \(X_1,\ldots,X_N\) be i.i.d. random variables of mean \(\E[X_n] = \mu\) and variance \(\Var[X_n] = \sigma^2\). Also, assume that \(\E[|X_n^3|] < \infty\). Let \(\overline{X}_N = (1/N) \sum_{n=1}^N X_n\) be the sample average, and let \(Z_N = \sqrt{N}\left(\frac{\overline{X}_N-\mu}{\sigma}\right)\). Then
where \(Z = \text{Gaussian}(0,1)\).
In plain words, the Central Limit Theorem says that the sample average (which is a random variable) has a CDF converging to the CDF of a Gaussian. Therefore, if we want to evaluate probabilities associated with the sample average, we can approximate the probability by the probability of a Gaussian.
As we discussed above, the Central Limit Theorem does not mean that the random variable \(Z_N\) is converging to a Gaussian random variable, nor does it mean that the PDF of \(Z_N\) is converging to the PDF of a Gaussian. It only means that the CDF of \(Z_N\) is converging to the CDF of a Gaussian. Many people think that the Central Limit Theorem means “sample average converges to Gaussian”. This is incorrect for the above reasons. However, it is not completely wrong. For continuous random variables where both PDF and CDF are continuous, we will not run into situations where the PDF is a train of delta functions. In this case, convergence in CDF can be translated to convergence in PDF.
The power of the Central Limit Theorem is that the result holds for any distribution of \(X_1,\ldots,X_N\). That is, regardless of the distribution of \(X_1,\ldots,X_N\), the CDF of \(\overline{X}_N\) is approaching a Gaussian.
- sep0ex
- \(X_1,\ldots,X_N\) are i.i.d. random variables, with mean \(\mu\) and variance \(\sigma^2\). They are not necessarily Gaussians.
- Define the sample average as \(\overline{X}_N = (1/N)\sum_{n=1}^N X_n\), and let \(Z_N = \sqrt{N}\left(\frac{\overline{X}_N-\mu}{\sigma}\right)\).
- The Central Limit Theorem says \(Z_N \overset{d}{\longrightarrow} \text{Gaussian}(0,1)\). Equivalently, the theorem says that \(\sqrt{N}(\overline{X}_N - \mu) \overset{d}{\longrightarrow} \text{Gaussian}(0,\sigma^2)\).
So if we want to evaluate the probability of \(\overline{X}_N \in \calA\) for some set \(\calA\), we can approximate the probability by evaluating the Gaussian:
$$\Pb[ \overline{X}_N \in \calA] \approx \int_{\calA} \frac{1}{\sqrt{2\pi(\sigma^2/N)}} \exp\left\{-\frac{(y-\mu)^2}{2(\sigma^2/N)}\right\} \;dy.$$- CLT does not say that the PDF of \(\overline{X}_N\) is becoming a Gaussian PDF.
- CLT only says that the CDF of \(\overline{X}_N\) is becoming a Gaussian CDF.
If the set \(\calA\) is an interval, we can use the standard Gaussian CDF to compute the probability.
Let \(X_1,\ldots,X_N\) be i.i.d. random variables with mean \(\mu\) and variance \(\sigma^2\). Define the sample average as \(\overline{X}_N = (1/N)\sum_{n=1}^N X_n\). Then
where \(\Phi(z) = \int_{-\infty}^z \frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}}\;dx\) is the CDF of the standard Gaussian.
Proof. By the Central Limit Theorem, we know that \(\overline{X}_N \overset{d}{\longrightarrow} \text{Gaussian}(\mu, \frac{\sigma^2}{N})\). Therefore,
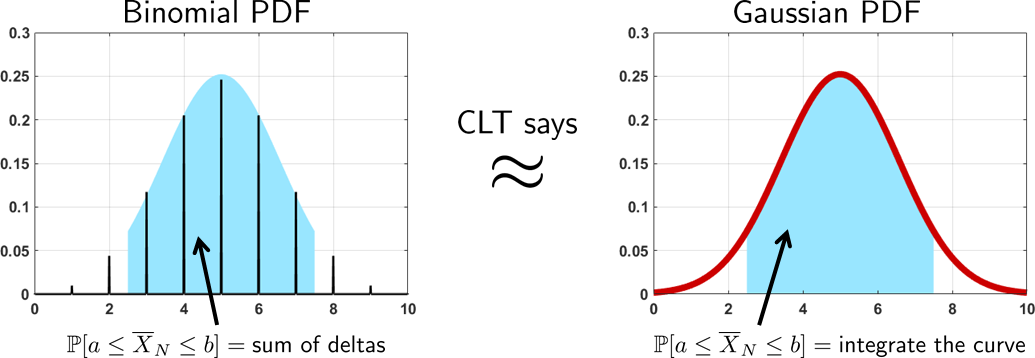
A graphical illustration of the CLT is shown in Figure 6.18, where we use a binomial random variable (which is the sum of i.i.d. Bernoulli) as an example. The CLT does not say that the binomial random variable is becoming a Gaussian. It only says that the probability covered by the binomial can be approximated by the Gaussian.
The following proof of the Central Limit Theorem can be skipped if this is your first time reading the book.
Proof of the Central Limit Theorem. We now give a “proof” of the Central Limit Theorem. Technically speaking, this proof does not prove the convergence of the CDF as the theorem claims; it only proves that the moment-generating function converges. The actual proof of the CDF convergence is based on the Berry-Esseen Theorem, which is beyond the scope of this book. However, what we prove below is still useful because it gives us some intuition about why Gaussian is the limiting random variable we should consider in the first place.
Let \(Z_N = \sqrt{N}\left( \frac{\overline{X}_N - \mu}{\sigma}\right)\). It follows that \(\E[Z_N] = 0\) and \(\Var[Z_N] = 1\). Therefore, if we can show that \(Z_N\) is converging to a standard Gaussian random variable \(Z \sim \text{Gaussian}(0,1)\), then by the linear transformation property of Gaussian, \(Y = \frac{\sigma}{\sqrt{N}} Z + \mu\) will be \(\text{Gaussian}(\mu,\sigma^2/N)\).
Our proof is based on analyzing the moment-generating function of \(Z_N\). In particular,
Expanding the exponential term using the Taylor expansion (Chapter 1.2),
It remains to show that \(\left(1+\frac{s^2}{2N}\right)^N \rightarrow e^{s^2/2}\). If we can show that, we have shown that the MGF of \(Z_N\) is also the MGF of \(\text{Gaussian}(0,1)\). To this end, we consider \(\log(1+x)\). By the Taylor approximation, we have that
Therefore, we have \(\log\left(1+\frac{s^2}{2N}\right) \approx \frac{s^2}{2N} - \frac{s^4}{8N^2}\). As \(N \rightarrow \infty\), the limit becomes
and so taking the exponential on both sides yields \(\lim_{N\rightarrow\infty} \left(1+\frac{s^2}{2N}\right)^N = e^{\frac{s^2}{2}}\). Therefore, we conclude that \(\lim_{N \rightarrow \infty} M_{Z_N}(s) = e^{\frac{s^2}{2}}\), and so \(Z_N\) is converging to a Gaussian.
■Limitation of our proof. The limitation of our proof lies in the issue of whether the integration and the limit are interchangeable:
If they were, then proving \(\lim_{N\rightarrow\infty} M_{Z_N}(s) = M_Z(s)\) is sufficient to claim \(f_{Z_N}(z) \rightarrow f_Z(z)\). However, we know that the latter is not true in general. For example, if \(f_{Z_N}(z)\) is a train of delta functions, then the limit and the integration are not interchangeable.
Berry-Esseen Theorem. The formal way of proving the Central Limit Theorem is to prove the Berry-Esseen Theorem. The theorem states that
where \(\beta\) and \(C\) are universal constants. Here, you can more or less treat the supremum operator as the maximum. The left-hand side represents the worst-case error of the CDF \(F_{Z_N}\) compared to the limiting CDF \(F_Z\). The right-hand side involves several constants \(C\), \(\beta\), and \(\sigma\), but they are fixed.
As \(N\) goes to infinity, the right-hand side will converge to zero. Therefore, if we can prove this result, then we have proved the actual Central Limit Theorem. In addition, we have found the rate of convergence since the right-hand side tells us that the error drops at the rate of \(1/\sqrt{N}\), which is not particularly fast but is sufficient for our purpose. Unfortunately, proving the Berry-Esseen theorem is not easy. One of the difficulties, for example, is that one needs to deal with the infinite convolutions in the time domain or the frequency domain.
Interpreting our proof. If our proof is not completely valid, why do we mention it? For one thing, it provides us with some useful intuition. For most of the (well-behaving) random variables whose moments are finite, the exponential term in the moment-generating function can be truncated to the second-order polynomial. Since a second-order polynomial is a Gaussian, it naturally concludes that as long as we can perform such truncation the truncated random variable will be Gaussian.
To convince you that the Gaussian MGF is the second-order approximation to other MGFs, we use Bernoulli as an example. Let \(X_1,\ldots,X_N\) be i.i.d. Bernoulli with a parameter \(p\). Then the moment-generating function of \(\overline{X}_N = (1/N)\sum_{n=1}^N X_n\) would be:
Using the logarithmic approximation, it follows that
Taking the exponential on both sides, we have that
which is the MGF of a Gaussian random variable \(Y \sim \text{Gaussian}\left(p, \frac{p(1-p)}{N}\right)\).
Figure 6.19 shows several MGFs. In each of the subfigures we plot the exact MGF \(M_{\overline{X}_N}(s) = (1-p+pe^{\frac{s}{N}})^N\) as a function of \(s\). (The parameter \(p\) in this example is \(p = 0.5\).) We vary the number \(N\), and we inspect how the shape of \(M_{\overline{X}_N}(s)\) changes. On top of the exact MGFs, we plot the Gaussian approximations \(M_Y(s) = \exp\left\{sp + \frac{s^2p(1-p)}{2N}\right\}\). According to our calculation, this Gaussian approximation is the second-order approximation to the exact MGF. The figures show the effect of the second-order approximation. For example, in (a) when \(N = 2\) the Gaussian is a quadratic approximation of the exact MGF. For (b) and (c), as \(N\) increases, the approximation improves.
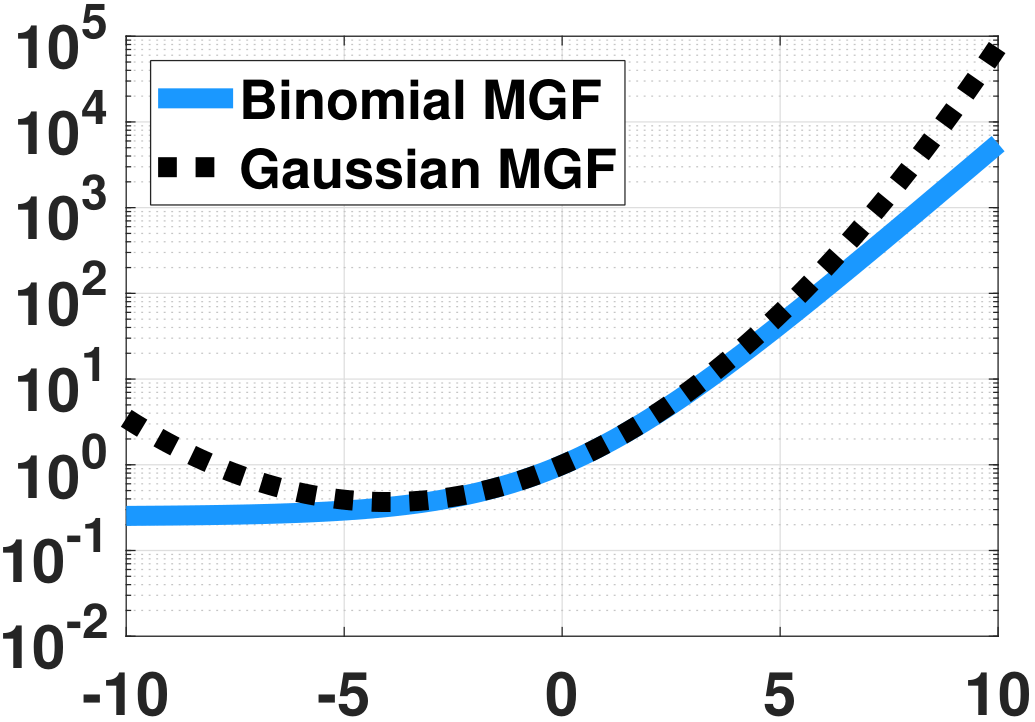
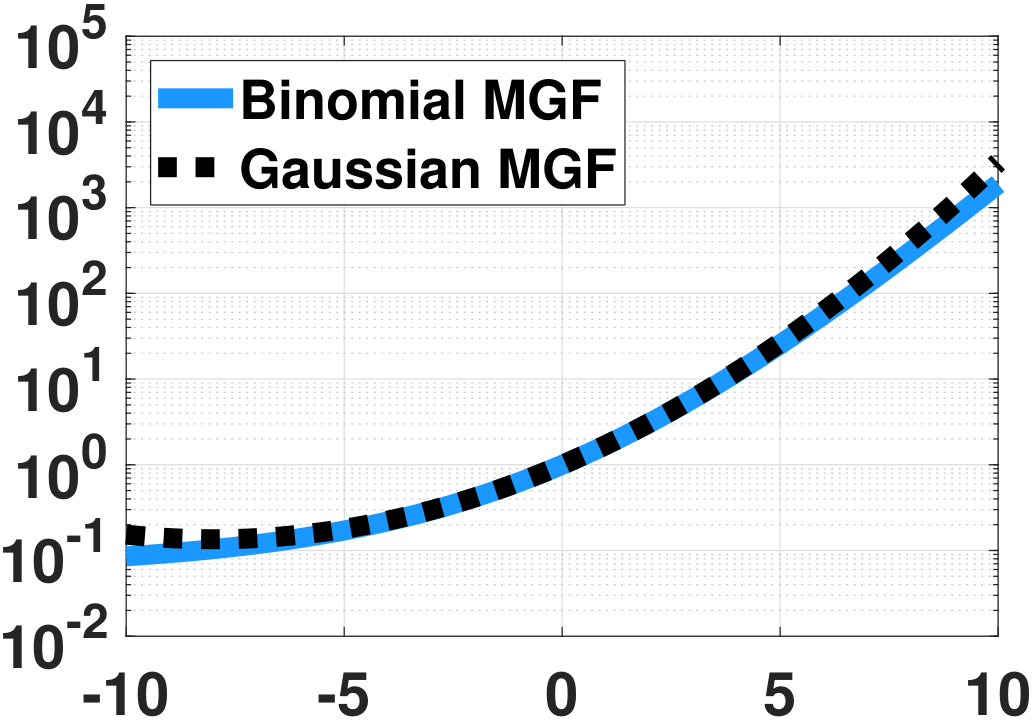
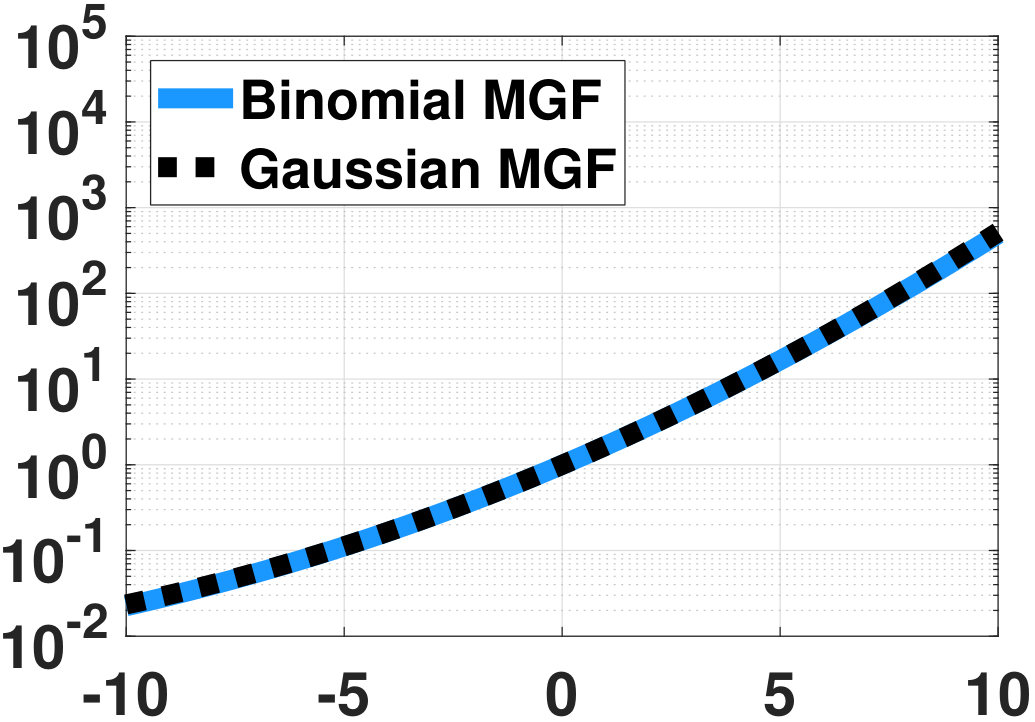
The reason why the second-order approximation works for Gaussian is that when \(N\) increases, the higher order moments of \(\overline{X}_N\) vanish and only the leading first two moments survive. The MGFs are becoming flat because \(M_Y(s) = \exp\left\{sp + \frac{s^2p(1-p)}{2N}\right\}\) converges to \(\exp\{sp\}\) when \(N \rightarrow \infty\). Taking the inverse Laplace transform, \(M_Y(s) = \exp\{sp\}\) corresponds to a delta function. This makes sense because as \(N\) grows, the variance of \(\overline{X}_N\) shrinks.
End of the discussion.
6.4.3Examples
Prove the equivalence of two statements.
- sep0ex
- \(\sqrt{N}\left(\frac{\overline{X}_N-\mu}{\sigma}\right) \overset{d}{\rightarrow} \text{Gaussian}(0,1)\)
- \(\sqrt{N}(\overline{X}_N-\mu) \overset{d}{\rightarrow} \text{Gaussian}(0,\sigma^2)\)
The proof is based on the linear transformation property of Gaussian random variables. For example, if the first statement is true, then the second statement is also true because
The other results can be proved similarly.
Suppose \(X_n \sim \mathrm{Poisson}(10)\) for \(n = 1,\ldots,N\), and let \(\overline{X}_N\) be the sample average. Use the Central Limit Theorem to approximate \(\Pb[9 \le \overline{X}_N \le 11]\) for \(N = 20\).
We first show that
Therefore, the Central Limit Theorem implies that \(\overline{X}_N \overset{d}{\longrightarrow} \text{Gaussian}\left(10,\frac{1}{2}\right)\). The probability is
We can also do an exact calculation to verify our approximation. Let \(S_N = \sum_{n=1}^N X_n\) so that \(\overline{X}_N = \frac{S_N}{N}\). Since a sum of Poisson remains a Poisson, it follows that
Consequently,
Note that this is an exact calculation subject to numerical errors when evaluating the finite sums.
Suppose you have collected \(N = 100\) data points from an unknown distribution. The only thing you know is that the true population mean is \(\mu = 500\) and the standard deviation is \(\sigma = 80\). (Note that this distribution is not necessarily a Gaussian.)
- sep0ex
- (a) Find the probability that the sample mean will be inside the interval \((490,510)\).
- (b) Find an interval such that 95% of the sample average is covered.
To solve (a), we note that \(\overline{X}_N \overset{d}{\rightarrow} \text{Gaussian}\left(500, \left(\tfrac{80}{\sqrt{100}}\right)^2\right)\). Therefore,
To solve (b), we know that \(\Phi(x) = 0.025\) implies that \(x = -1.96\), and \(\Phi(x) = 0.975\) implies that \(x = +1.96\). So
Therefore, \(\Pb[484.32 \le \overline{X}_N \le 515.68] = 0.95\).
6.4.4Limitation of the Central Limit Theorem
If we recall the statement of the Central Limit Theorem (Berry-Esseen), we observe that the theorem states only that
Rearranging the terms,
This implies that the approximation is good only when the deviation \(\varepsilon\) is small.
Let us consider an example to illustrate this idea. Consider a set of i.i.d. exponential random variables \(X_1,\ldots,X_N\), where \(X_n \sim \text{Exponential}(\lambda)\). Let \(S_N = X_1+\cdots+X_N\) be the sum, and let \(\overline{X}_N = S_N/N\) be the sample average. Then, according to Chapter 6.4.1, \(S_N\) is an Erlang distribution \(S_N \sim \text{Erlang}(N,\lambda)\) with a PDF
Let \(S_N \sim \text{Erlang}(N,\lambda)\) with a PDF \(f_{S_N}(x)\). Show that if \(Y_N = aS_N + b\) for any constants \(a\) and \(b\), then
: This is a simple transformation of random variables:
Hence, using the fundamental theorem of calculus,
We are interested in knowing the statistics of \(\overline{X}_N\) and comparing it with a Gaussian. To this end, we construct a normalized variable
where \(\mu = \E[X_n] = \frac{1}{\lambda}\) and \(\sigma^2 = \Var[X_n] = \frac{1}{\lambda^2}\). Then
Using the result of the practice exercise, by mapping \(a = \frac{\lambda}{\sqrt{N}}\) and \(b = -\sqrt{N}\), it follows that
Now we compare \(Z_N\) with the standard Gaussian \(Z \sim \text{Gaussian}(0,1)\). According to the Central Limit Theorem, the standard Gaussian is a good approximation to the normalized sample average \(Z_N\). To compare the two results, we conduct a numerical experiment. We let \(\lambda = 1\) and we vary \(N\). We plot the PDF \(f_{Z_N}(z)\) as a function of \(z\), for different \(N\)'s, in Figure 6.20. In addition, we plot the PDF \(f_Z(z)\), which is the standard Gaussian.
The plot in Figure 6.20 shows that while the Central Limit Theorem provides a good approximation, the approximation is only good for values that are close to the mean. For the tails, the Gaussian approximation is not as good.
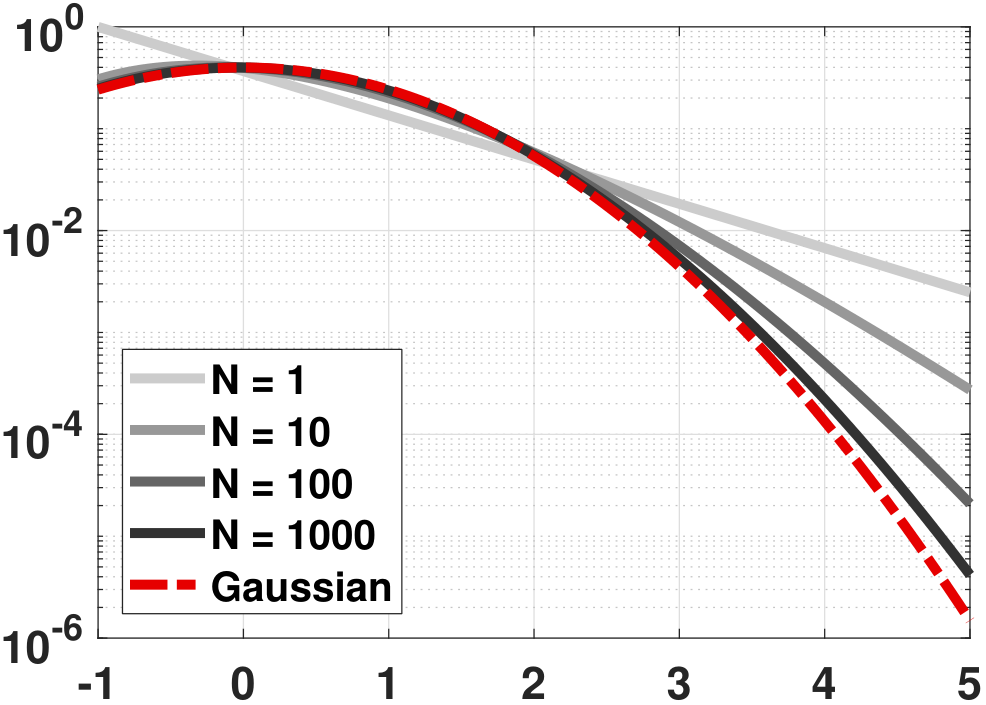
The limitation of the Central Limit Theorem is attributable to the fact that Gaussian is a second-order approximation. If a random variable has a very large third moment, the second-order approximation may not be sufficient. In this case, we need a much larger \(N\) to drive the third moment to a small value and make the Gaussian approximation valid.
- sep0ex
- The Central Limit Theorem fails when \(N\) is small.
- The Central Limit Theorem fails if the third moment is large. As an extreme case, a Cauchy random variable does not have a finite third moment. The Central Limit Theorem is not valid for this case.
- The Central Limit Theorem can only approximate the probability for input values near the mean. It does not approximate the tails, for which we need to use Chernoff's bound.