Optimal Linear Filter
In the previous sections, we have built many tools to analyze random processes. Our next goal is to apply these techniques. To that end, we will discuss optimal linear filter design, which is a set of estimation techniques for predicting and recovering information from a time series.
10.6.1Discrete-time random processes
We begin by introducing some notations. In the previous sections, we have been using continuous-time random processes to study statistics. In this section, we mainly focus on discrete-time random processes. The shift from continuous-time to discrete-time is straightforward as far as the theories are concerned — we switch the continuous-time index \(t\) to a discrete-time index \(n\). However, shifting to discrete-time random processes can simplify many difficult problems because many discrete-time problems can be solved by matrices and vectors. This will make the computations and implementations much easier. To make this transition easier, we provide a few definitions and results without proof.
Notations for discrete-time random processes
- sep0ex
- We denote the discrete-time indices by \(m\) and \(n\), corresponding to the continuous-time indices \(t_1\) and \(t_2\), respectively.
- A discrete-time random process is denoted by \(X[n]\).
Its mean function and the autocorrelation function are
$$\begin{aligned} \mu_X[n] &= \E[X[n]],\\ R_X[m,n] &= \E[X[m]X[n]]. \end{aligned}$$- We say that \(X[n]\) is WSS if \(\mu_X[n] =\) constant, and \(R_X[m,n]\) is a function of \(m-n\).
If \(X[n]\) is WSS, we write \(R_X[m,n]\) as
$$R_X[m,n] = R_X[m-n] = R_X[k],$$where \(k = m-n\) is the interval.
If \(X[n]\) is WSS, we define the power spectral density as
$$S_X(e^{j\omega}) = \calF\{R_X[k]\},$$where \(S_X(e^{j\omega})\) denotes the discrete-time Fourier transform.
When a random process \(X[n]\) is sent through an LTI system with an impulse response \(h[n]\), the output is
When a WSS process \(X[n]\) passes through an LTI system \(h[n]\) to yield an output \(Y[n]\), the auto- and cross-correlation function and power spectral densities are
- sep0ex
- \(R_Y[k] = \E[Y[n+k]Y[n]]\), \(S_Y(e^{j\omega}) = \calF\{R_Y[k]\} = |H(e^{j\omega})|^2S_X(e^{j\omega})\).
- \(R_{XY}[k] = \E[X[n+k]Y[n]]\), \(S_{XY}(e^{j\omega}) = \calF\{R_{XY}[k]\} = \overline{H(e^{j\omega})}S_X(e^{j\omega})\).
- \(R_{YX}[k] = \E[Y[n+k]X[n]]\), \(S_{YX}(e^{j\omega}) = \calF\{R_{YX}[k]\} = H(e^{j\omega})S_X(e^{j\omega})\).
10.6.2Problem formulation
The problem we study here is known as the optimal linear filter design. Suppose that there is a WSS process \(X[n]\) that we want to process. For example, if \(X[n]\) is a corrupted version of some clean time-series, we may want to remove the noise by filtering (also known as averaging) \(X[n]\). Conceptualizing the denoising process as a linear time-invariant system with an impulse response \(h[n]\), our goal is to determine the optimal \(h[n]\) such that the estimated time series \(\widehat{Y}[n]\) is as close to the true time series \(Y[n]\) as possible.
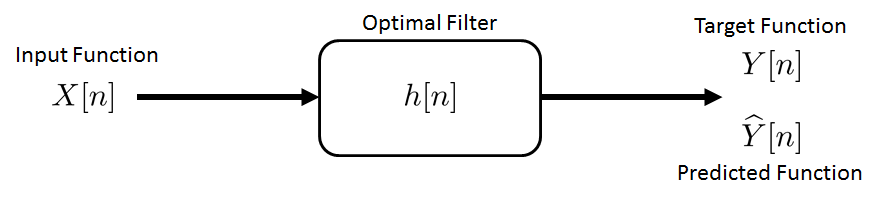
Referring to Figure 10.24, we refer to \(X[n]\) as the input function and to \(Y[n]\) as the target function. \(X[n]\) and \(Y[n]\) are related according to the equation
where \(E[n]\) is a noise random process to model the error. The linear part of the equation is known as the prediction and is constructed by sending \(X[n]\) through the system. For simplicity we assume that \(X[n]\) is WSS. Thus, it follows that \(Y[n]\) is also WSS. We may also assume that we can estimate \(R_X[k]\), \(R_{YX}[k]\), \(R_{XY}[k]\) and \(R_{Y}[k]\).
If we let \(K = 3\), Eq. (10.34) gives us
That is, the current sample \(Y[n]\) is a linear combination of the previous samples \(X[n]\), \(X[n-1]\) and \(X[n-2]\).
Given \(X[n]\) and \(Y[n]\), what would be the best guess of the impulse response \(h[n]\) so that the prediction is as close to the true values as possible? From our discussions of linear regression, we know that this is equivalent to solving the optimization problem
The choice of the squared error is more or less arbitrary, depending on how we want to model \(E[n]\). By using the squared norm, we implicitly assume that the error is Gaussian. This may not be true, but it is commonly used because the squared norm is differentiable. We will follow this tradition.
The challenge associated with the minimization is that in most of the practical settings the random processes \(X[n]\) and \(Y[n]\) are changing rapidly because they are random processes. Therefore, even if we solve the optimization problem, the estimates \(h[k]\) will be random variables since we are solving a random equation. To eliminate this randomness, we take the expectation over all the possible choices of \(X[n]\) and \(Y[n]\), yielding
The resulting impulse response \(h[k]\), derived by solving the above minimization, is known as the optimal linear filter. It is the best linear model for describing the input-output relationships between \(X[n]\) and \(Y[n]\).
The optimal linear filter is the solution to the optimization problem
10.6.3Yule-Walker equation
To solve the optimal linear filter problem, we first perform some (slightly tedious) algebra to obtain the following results:
Let \(\widehat{Y}[n] = \sum_{k=0}^{K-1} h[k]X[n-k]\) be the prediction of \(Y[n]\). The squared-norm error can be written as
Thus we can express the error in terms of \(R_{YX}[k]\), \(R_X[k]\) and \(R_Y[k]\).
Proof. We expand the error as follows:
The first term is the autocorrelation of \(Y[n]\):
The second term is
The third term is
This completes the proof.
■The significance of this theorem is that it allows us to write the error in terms of \(R_{YX}[k]\), \(R_X[k]\) and \(R_Y[k]\). As we have mentioned, while we can solve the randomized optimization Eq. (10.35), the resulting solution will be a random vector depending on the particular realizations \(X[n]\) and \(Y[n]\). Switching from Eq. (10.35) to Eq. (10.36) eliminates the randomness because we have taken the expectation. The resulting optimization according to the theorem is also convenient. Instead of seeking individual realizations, we only need to know the overall statistical description of the data through \(R_{YX}[k]\), \(R_X[k]\) and \(R_Y[k]\). These can be estimated through modeling or pseudorandom signals.
The solution to the optimal linear filter problem is summarized by the Yule-Walker equation:
The solution \(\{h[0],\ldots,h[K-1]\}\) to the optimal linear filter problem
is given by the following matrix equation:
which is known as the Yule-Walker equation.
Therefore, by solving the simple linear problem given by the Yule-Walker equation, we will find the optimal linear filter solution.
Proof. Since the error is a squared norm, the optimal solution is obtained by taking the derivative:
in which the derivative of the last term is computed by noting that
Equating the derivative to zero yields
and putting the above equations into the matrix-vector form we complete the proof.
■The matrix in the Yule-Walker equation is a Toeplitz matrix, in which each row is a shifted version of the preceding row. This matrix structure is a consequence of a WSS process so that the autocorrelation function is determined by the time difference \(k\) and not by the starting and end times.
Remark. If we take the derivative of the loss w.r.t. \(h[i]\), we have that
This condition is known as the orthogonality condition, as it says that the error \(Y[n]-\widehat{Y}[n]\) is orthogonal to the signal \(X[n-i]\).
10.6.4Linear prediction
We now demonstrate how to use the Yule-Walker equation in modeling an autoregressive process. The procedure in this simple example can be used in speech processing and time-series forecasting.
Suppose that we have a WSS random process \(Y[n]\). We would like to predict the future samples by using the most recent \(K\) samples through an autoregressive model. Since the model is linear, we can write
In this model, we say that the predicted value \(\widehat{Y}[n]\) is a linear combination of the past \(K\) samples, albeit with an approximation error \(E[n]\).
The problem we need to solve is
Since \(\widehat{Y}[n]\) is written in terms of the past samples of \(Y[n]\) in this problem, in the Yule-Walker equation we can replace \(X\) with \(Y\). Consequently, we can write the matrix equation from
to
On a computer, solving the Yule-Walker equation requires a few steps. First, we need to estimate the correlation
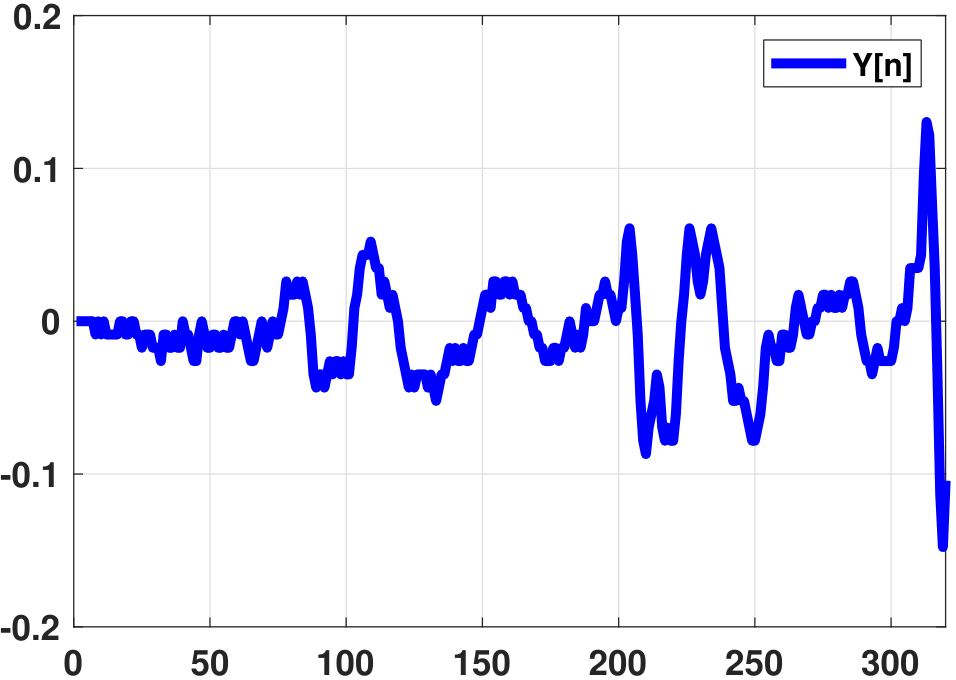
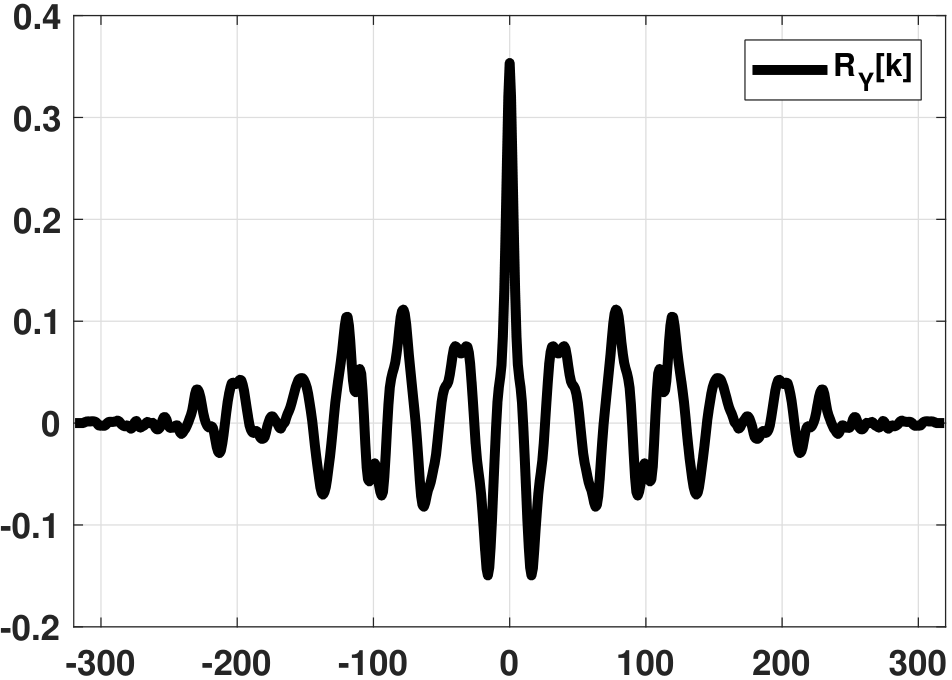
The averaging on the right-hand side is often done using xcorr in MATLAB or np.correlate in Python. A graphical illustration of the input and the autocorrelation function is shown in Figure 10.25.
After we have found \(R_Y[k]\), we need to construct the Yule-Walker equation. For this linear prediction problem, the left-hand side of the Yule-Walker equation is the vector \(\vr\), defined according to Eq. (10.44). The Yule-Walker equation also requires the matrix \(\mR\). This \(\mR\) can be constructed via the Toeplitz matrix as
In MATLAB, we can call Toeplitz to construct the matrix. In Python, the command is lin.Toeplitz.
To solve the Yule-Walker equation, we need to invert the matrix \(\mR\). There are built-in commands for such an operation. In MATLAB, the command is \ (the backslash), whereas in Python the command is np.linalg.lstsq.
% MATLAB code to solve the Yule Walker Equation
y = load('data_ch10.txt');
K = 10;
N = 320;
y_corr = xcorr(y);
R = Toeplitz(y_corr(N+[0:K-1]));
lhs = y_corr(N+[1:K]);
h = R\lhs;# Python code to solve the Yule Walker Equation
y = np.loadtxt('./data_ch10.txt')
K = 10
N = 320
y_corr = np.correlate(y,y,mode='full')
R = lin.Toeplitz(y_corr[N-1:N+K-1]) #call scipy.linalg
lhs = y_corr[N:N+K]
h = np.linalg.lstsq(R,lhs,rcond = None)[0]Note that in both the MATLAB and Python codes the Toeplitz matrix \(\mR\) starts with the index \(N\). This is because, as you can see from Figure 10.25, the origin of the autocorrelation function is the middle index of the computed autocorrelation function. For \(\vr\), the starting index is \(N+1\) because the vector starts with \(R_Y[1]\).
To predict the future samples, we recall the autoregressive model for this problem:
Therefore, given \(Y[n-1],Y[n-2],\ldots,Y[n-K]\), we can predict \(\widehat{Y}[n]\). Then we insert this predicted \(\widehat{Y}[n]\) into the sequence and increment the estimation problem to the next time index. By repeating the process, we will be able to predict the future samples of \(Y[n]\).
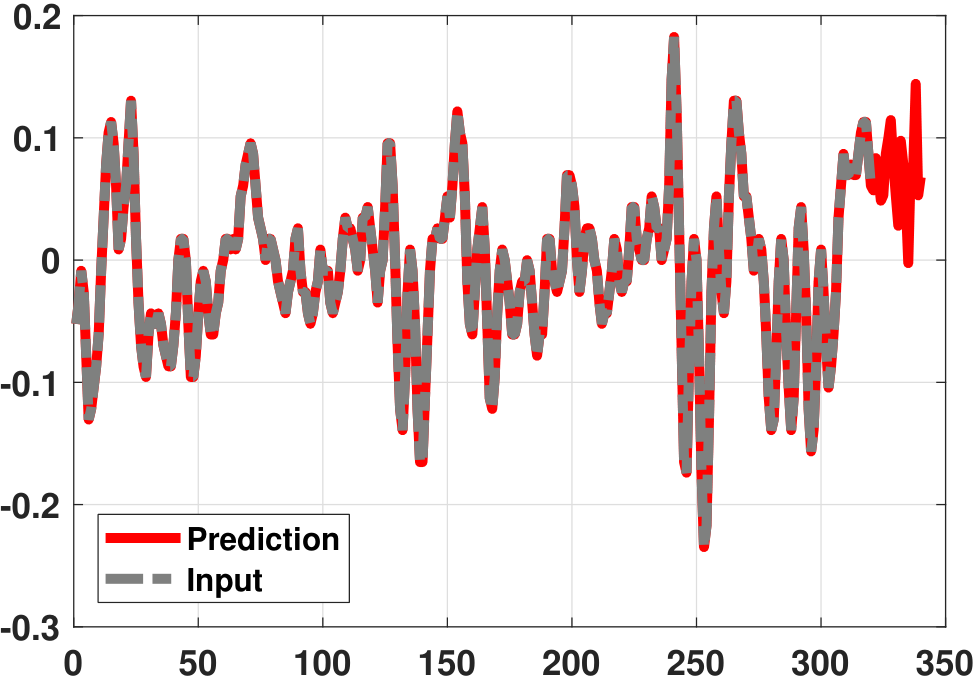
Figure 10.26 illustrates the prediction results of the Yule-Walker equation. As you can see, the predictions are reasonably meaningful since the patterns follow the trend.
The MATLAB and Python codes are shown below.
% MATLAB code to predict the samples
z = y(311:320);
yhat = zeros(340,1);
yhat(1:320) = y;
for t = 1:20
predict = z'*h;
z = [z(2:10); predict];
yhat(320+t) = predict;
end
plot(yhat, 'r', 'LineWidth', 3); hold on;
plot(y, 'k', 'LineWidth', 4);# Python code to predict the samples
z = y[310:320]
yhat = np.zeros((340,1))
yhat[0:320,0] = y
for t in range(20):
predict = np.inner(np.reshape(z,(1,10)),h)
z = np.concatenate((z[1:10], predict))
yhat[320+t,0] = predict
plt.plot(yhat,'r')
plt.plot(y,'k')
plt.show()10.6.5Wiener filter
In the previous formulation, we notice that the impulse response has a finite length. There are, however, problems in which the impulse response is infinite. For example, a recursive filter \(h[n]\) will be infinitely long. The extension from finite length to infinite length is straightforward. We can model the problem as
However, when \(h[n]\) is infinitely long the Yule-Walker equation does not hold because the matrix \(\mR\) will be infinitely large. Nevertheless, the building block equation for Yule-Walker is still valid:
To maintain the spirit of the Yule-Walker equation while enabling computation, we recognize that the infinite sum on the right-hand side is, in fact, a convolution. Thus we can take the (discrete-time) Fourier transform of both sides to obtain
Therefore, the corresponding optimal linear filter (in the Fourier domain) is
and
The filter obtained in this way is known as the Wiener filter.
(Denoising) Suppose \(X[n] = Y[n] + W[n]\), where \(W[n]\) is the noise term that is independent of \(Y[n]\), as shown in Figure 10.27.

Now, given the input function \(X[n]\), can we construct the Wiener filter \(h[n]\) such that the predicted function \(\widehat{Y}[n]\) is as close to \(Y[n]\) as possible? The Wiener filter for this problem is also the optimal denoising filter.
The following correlation functions can easily be seen:
Similarly, we have
Consequently, the optimal linear filter is
- Suppose the corrupted function \(X[n]\) is related to the clean function \(Y[n]\) through \(X[n] = Y[n] + W[n]\), for some noise function \(W[n]\).
The Wiener filter is
$$H(e^{j\omega}) = \frac{S_{Y}(e^{j\omega})}{S_Y(e^{j\omega}) + S_{W}(e^{j\omega})}.$$To perform the filtering, the denoised function \(\widehat{Y}[n]\) is
$$\widehat{Y}[n] = \calF^{-1}\left\{ H(e^{j\omega}) X(e^{j\omega})\right\}.$$
Figure 10.28 shows an example of applying the Wiener filter to a noise removal problem. In this example we let \(W[n]\) be an i.i.d. Gaussian process with standard deviation \(\sigma = 0.05\) and mean \(\mu = 0\). The noisy samples of random process \(X[n]\) are defined as \(X[n] = Y[n] + W[n]\), where \(Y[n]\) is the clean function. As you can see from Figure 10.28(a), the Wiener filter is able to denoise the function reasonably well.
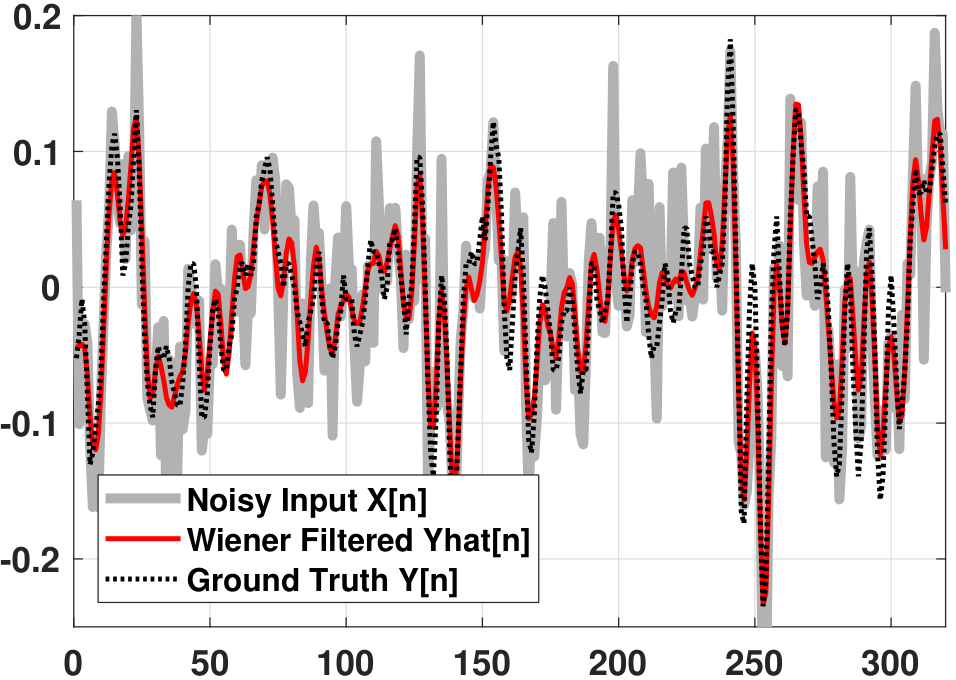
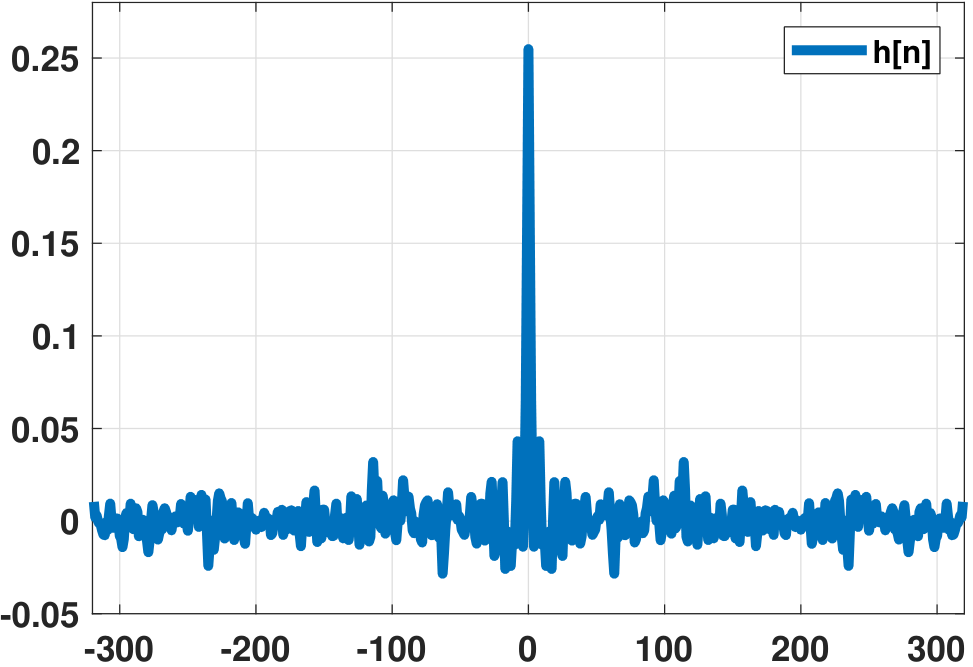
The optimal linear filter used for this denoising task is infinitely long. This can be seen in Figure 10.28(b), where the filter length is the same as the length of the observed time series \(X[n]\). If \(X[n]\) is longer, the filter \(h[n]\) will also become longer. Therefore, finite-length approaches such as the Yule-Walker equation do not apply here.
The MATLAB / Python codes used to generate Figure 10.28(a) are shown below. The main commands here are scipy.fft and scipy.ifft, which are available in the scipy library. The commands Yhat = H.*fft(x, 639) in MATLAB execute the Wiener filtering step. Here, we resample the function x to 639 samples so that it matches with the Wiener filter H. Similar commands in Python are H * fft(x, 639).
% MATLAB code for Wiener filtering
w = 0.05*randn(320,1);
x = y + w;
Ry = xcorr(y);
Rw = xcorr(w);
Sy = fft(Ry);
Sw = fft(Rw);
H = Sy./(Sy + Sw);
Yhat = H.*fft(x, 639);
yhat = real(ifft(Yhat));
plot(x, 'LineWidth', 4, 'Color', [0.7, 0.7, 0.7]); hold on;
plot(yhat(1:320), 'r', 'LineWidth', 2);
plot(y, 'k:', 'LineWidth', 2);# Python code for Wiener filtering
from scipy.fft import fft, ifft
w = 0.05*np.random.randn(320)
x = y + w
Ry = np.correlate(y,y,mode='full')
Rw = np.correlate(w,w,mode='full')
Sy = fft(Ry)
Sw = fft(Rw)
H = Sy / (Sy+Sw)
Yhat = H * fft(x, 639)
yhat = np.real(ifft(Yhat))
plt.plot(x,color='gray')
plt.plot(yhat[0:320],'r')
plt.plot(y,'k:')(Deconvolution) Suppose that the corrupted function is generated according to a linear process given by
where \(g[n]\) is the impulse response of some kind of degradation process and \(W[n]\) is the Gaussian noise term, as shown in Figure 10.29. Find the optimal linear filter (i.e., the Wiener filter) to estimate \(\widehat{Y}[n]\).

To construct the Wiener filter, we first determine the cross-correlation function:
Using algebra, it follows that
which is the correlation between \(g\) and \(R_Y\). Therefore, the cross power spectral density \(S_{YX}(e^{j\omega})\) is
The autocorrelation of this problem is
where, according to the previous section, the first part is the correlation \(\circledast\) followed by a convolution \(\ast\). Therefore, the power spectral density of \(X\) is
Combining the results, the Wiener filter is
- Suppose that the corrupted function \(X[n]\) is related to the clean function \(Y[n]\) through \(X[n] = (g \ast Y)[n] + W[n]\), for some degradation \(g[n]\) and noise \(W[n]\).
The Wiener filter is
$$H(e^{j\omega}) = \frac{\overline{G(e^{j\omega})}S_Y(e^{j\omega})}{|G(e^{j\omega})|^2 S_Y(e^{j\omega}) + S_W(e^{j\omega})}.$$To perform the filtering, the estimated function \(\widehat{Y}[n]\) is
$$\widehat{Y}[n] = \calF^{-1}\left\{ H(e^{j\omega}) X(e^{j\omega})\right\}.$$
As an example of the deconvolution problem, we show a WSS function \(Y[n]\) in Figure 10.30. This clean function \(Y[n]\) is constructed by passing an i.i.d. noise process through an arbitrary LTI system so that the WSS property is guaranteed. Given this \(Y[n]\), we construct a degradation process in which the impulse response is given by \(g[n]\). In this example, we assume that \(g[n]\) is a uniform function. We then add noise \(W[n]\) to the time series to obtain the corrupted observation \(X[n]\). The reconstruction by the Wiener filter is shown in Figure 10.30.
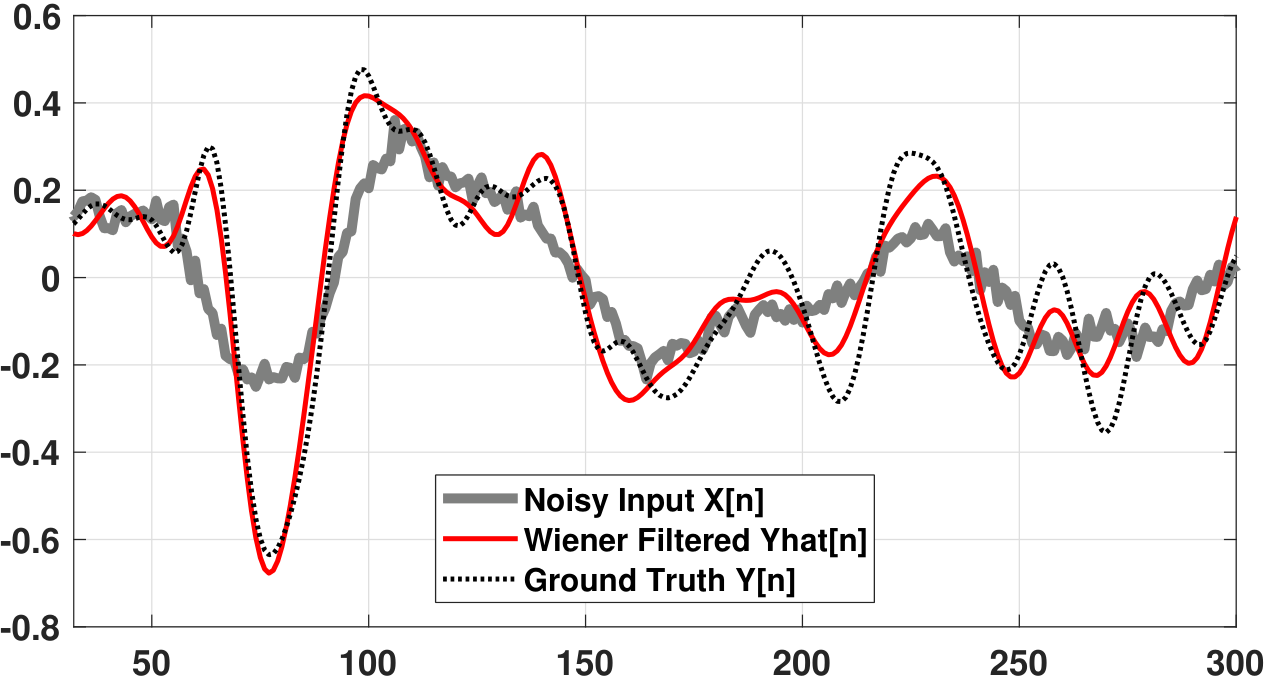
The MATLAB and Python codes used to generate Figure 10.30 are shown below.
% MATLAB code to solve the Wiener deconvolution problem
load('ch10_wiener_deblur_data');
g = ones(32,1)/32;
w = 0.02*randn(320,1);
x = conv(y,g,'same') + w;
Ry = xcorr(y);
Rw = xcorr(w);
Sy = fft(Ry);
Sw = fft(Rw);
G = fft(g,639);
H = (conj(G).*Sy)./(abs(G).^2.*Sy + Sw);
Yhat = H.*fft(x, 639);
yhat = real(ifft(Yhat));
figure;
plot(x, 'LineWidth', 4, 'Color', [0.5, 0.5, 0.5]); hold on;
plot(16:320+15, yhat(1:320), 'r', 'LineWidth', 2);
plot(1:320, y, 'k:', 'LineWidth', 2);# Python code to solve the Wiener deconvolution problem
y = np.loadtxt('./ch10_wiener_deblur_data.txt')
g = np.ones(64)/64
w = 0.02*np.random.randn(320)
x = np.convolve(y,g,mode='same') + w
Ry = np.correlate(y,y,mode='full')
Rw = np.correlate(w,w,mode='full')
Sy = fft(Ry)
Sw = fft(Rw)
G = fft(g,639)
H = (np.conj(G)*Sy)/( np.power(np.abs(G),2)*Sy + Sw )
Yhat = H * fft(x, 639)
yhat = np.real(ifft(Yhat))
plt.plot(x,color='gray')
plt.plot(np.arange(32,320+32),yhat[0:320],'r')
plt.plot(y,'k:')Caveat to Wiener filtering. In practice, the above Wiener filter needs to be modified because \(S_Y(e^{j\omega})\) and \(S_W(e^{j\omega})\) cannot be estimated from the data via the temporal correlation (as we did in the MATLAB/Python programs). The reason is that we never have access to \(Y[n]\) and \(W[n]\). In this case, one has to guess the power spectral densities \(S_Y(e^{j\omega})\) and \(S_W(e^{j\omega})\). The noise power \(S_W(e^{j\omega})\) is usually not difficult to estimate. For example, in the program we showed above, the noise power spectral density is Sw = 0.02^2*320 (MATLAB), which is the noise variance times the number of samples.
The signal \(S_Y(e^{j\omega})\) is often the hard part. In the absence of any knowledge about the ground truth's power spectral density, the Wiener filter does not work. However, for certain problems in which \(S_Y(e^{j\omega})\) can be predetermined by prior knowledge, the Wiener filter is guaranteed to be optimal — optimal in the mean-squared-error sense over the entire time axis.
Wiener filter versus ridge regression. The Wiener filter equation can be interpreted as a ridge regression. Denoting the forward observation model by
the corresponding ridge regression minimization is
If \(\mG\) is a convolutional matrix, the above solution can be written in the Fourier domain (by using the Fourier transform as the eigenvectors):
Comparing this “optimal linear filter” with the Wiener filter, we observe that the Wiener filter has slightly more generality:
Therefore, in the absence of \(S_Y(e^{j\omega})\) and assuming that \(S_W(e^{j\omega})\) is a constant (e.g., for Gaussian noise), the Wiener filter is exactly a ridge regression.